
Up until recently all of the documentation for both the Developer Gemini API and the Vertex Gemini API only told us how to make live calls to the API’s. What I mean by live calls is you send a call to the API and you get a response back. This works great if you have an application that is requesting information from the API and it needs the response back now. But … What if you don’t need the response back now.
What if you are doing image classification? What if you are just loading data for a later use? I have an app that I load pages form a large PDF file into Gemini one page at at time and have it create study questions for me. This works very well but again its not something that needs to be done live. Its something that I can run once and wont need to do it again for that PDF file. Well unless they come out with a new fancy model and I want new questions generated by that mode.
So what can we do? Well I build myself a script and run it all at once.
Batching with Vertex
Vertex recently released a new Preview offering called Batch predictions for Gemini it does basically what you would think it would do. It lets you load prompts to the AI in batches that are run as jobs you are notified when they are complete.
The really kicker here is that the prompts are loaded from Big Query and the results are inserted back into Big Query. Keeping everything nice clean and easy to access.
When I run the code it creates a batch job over in my Google Cloud account.
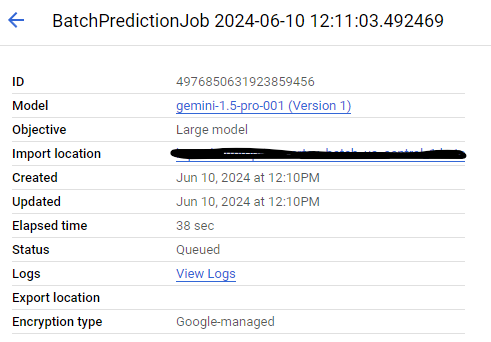
The Import location is the big query table where I have stored the data to be processed.
The Import table schema is simple enough it needs a single column called request of datatype JSON. Each rows should contain that of the request to be made. The format is the same as you would expect from your normal no batching request.
{
"contents": [
{
"role": "user",
"parts": {
"text": "Give me a recipe for banana bread."
}
}
],
"system_instruction": {
"parts": [
{
"text": "You are a chef."
}
]
},
"generation_config": {
"top_k": 5
}
}Once the processing is complete it creates a new table in the same database the table name is that of the job.
The table schema will have two columns request and response. The request column will contain the same Json that we sent
{"contents":[{"parts":{"text":"Give me a recipe for banana bread."},"role":"user"}],"generation_config":{"top_k":5},"system_instruction":{"parts":[{"text":"You are a chef."}]}}The response contains the response coming back from the API
[{"content": {"role": "model", "parts": [{"text": "## Grandma's Classic Banana Bread\n\nThis recipe is moist, flavorful, and perfect for using up those overripe bananas!\n\n**Ingredients:**\n\n* **Dry Ingredients:**\n * 2 cups all-purpose flour \n * 1 teaspoon baking soda\n * \u00bd teaspoon salt\n * \u00be cup granulated sugar\n * \u00bd cup packed light brown sugar \n* **Wet Ingredients:**\n * \u00bd cup unsalted butter, melted\n * 2 large eggs\n * 1 teaspoon vanilla extract\n * 1 cup mashed ripe bananas (about 2 \u00bd medium bananas)\n\n**Instructions:**\n\n1. **Preheat & Prep:** Preheat oven to 350\u00b0F (175\u00b0C). Grease and flour a 9x5 inch loaf pan.\n2. **Combine Dry Ingredients:** In a large bowl, whisk together flour, baking soda, salt, granulated sugar, and brown sugar.\n3. **Combine Wet Ingredients:** In a separate bowl, whisk together melted butter, eggs, and vanilla extract until well combined. Add mashed bananas and mix until just incorporated.\n4. **Combine Wet & Dry:** Gradually add the wet ingredients to the dry ingredients, mixing until just combined. Do not overmix. \n5. **Bake:** Pour batter into the prepared loaf pan and bake for 50-60 minutes, or until a wooden skewer inserted into the center comes out clean.\n6. **Cool:** Let the bread cool in the pan for 10 minutes before inverting it onto a wire rack to cool completely. \n\n**Chef's Tips:**\n\n* For extra banana flavor, use overripe bananas that are brown and spotty.\n* To prevent the bread from sticking to the pan, line the bottom of the pan with parchment paper. \n* If you prefer a sweeter bread, add \u00bd cup of chocolate chips or chopped nuts to the batter.\n* Store leftover banana bread at room temperature in an airtight container for up to 3 days.\n\n**Enjoy!** \n"}]}, "finishReason": "STOP", "safetyRatings": [{"category": "HARM_CATEGORY_HATE_SPEECH", "probability": "NEGLIGIBLE", "probabilityScore": 0.13568956, "severity": "HARM_SEVERITY_NEGLIGIBLE", "severityScore": 0.14767806}, {"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "probability": "NEGLIGIBLE", "probabilityScore": 0.11716747, "severity": "HARM_SEVERITY_NEGLIGIBLE", "severityScore": 0.12689333}, {"category": "HARM_CATEGORY_HARASSMENT", "probability": "NEGLIGIBLE", "probabilityScore": 0.19467382, "severity": "HARM_SEVERITY_NEGLIGIBLE", "severityScore": 0.11456649}, {"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "probability": "NEGLIGIBLE", "probabilityScore": 0.16079244, "severity": "HARM_SEVERITY_NEGLIGIBLE", "severityScore": 0.19698064}]}]Which model to use
I have been doing a lot of testing with Flash these days. So my initial tests with this were using gemini-1.5-flash-001 and not gemini-1.5-pro-001. However if you look closely at the image above you will see that the response I have pasted here was for gemini-1.5-pro-001and not for gemini-1.5-flash-001. Why is that?
Flash has issues.
When running the exact same request above against gemini-1.5.flash.001 I get the following results.
[{"finishReason": "RECITATION", "safetyRatings": [{"category": "HARM_CATEGORY_HATE_SPEECH", "probability": "NEGLIGIBLE", "probabilityScore": 0.101946525, "severity": "HARM_SEVERITY_NEGLIGIBLE", "severityScore": 0.1066906}, {"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "probability": "NEGLIGIBLE", "probabilityScore": 0.09384396, "severity": "HARM_SEVERITY_NEGLIGIBLE", "severityScore": 0.08977328}, {"category": "HARM_CATEGORY_HARASSMENT", "probability": "NEGLIGIBLE", "probabilityScore": 0.16518871, "severity": "HARM_SEVERITY_NEGLIGIBLE", "severityScore": 0.08359067}, {"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "probability": "NEGLIGIBLE", "probabilityScore": 0.14487323, "severity": "HARM_SEVERITY_NEGLIGIBLE", "severityScore": 0.14706452}], "citationMetadata": {"citations": [{"startIndex": 306, "endIndex": 460, "uri": "https://dibujacondidifood.com/posts/from-ripe-to-delight-unraveling-the-origins-of-banana-bread"}, {"startIndex": 391, "endIndex": 541, "uri": "https://github.com/quantumcognition/Crud-palm", "license": "MIT"}, {"startIndex": 748, "endIndex": 898, "uri": "https://allanimalsfaq.com/cow/how-to-make-cow-cookies/"}, {"startIndex": 940, "endIndex": 1073, "uri": "https://cookierecipesonline.com/claire-saffitz-chocolate-chip-cookies-recipe/"}, {"startIndex": 1115, "endIndex": 1258, "uri": "https://www.clicktohow.com/easy-and-delicious-banana-bread-recipe-for-any-occasion/"}]}}]RECITATION The token generation was stopped as the response was flagged for unauthorized citations.
finishreason
Flash won’t run it. I wonder if this could be fixed by changing some of the default settings. However when it comes to RECITATION it can be hard to fix the issue. As this is the default request given in the documentation I find it strange that it would throw this error.
The Code
.env
MODEL_ID=gemini-1.5-flash-001
PROJECT_ID=REDACTED
PROJECT_LOCATION=us-central1
BQ_TABLE_ID=REDACTED
BQ_OUTPUT_DATASET=REDACTEDvertex_batch.py
import os
import time
import vertexai
from vertexai.preview.batch_prediction import BatchPredictionJob
from dotenv import load_dotenv
load_dotenv()
def create_batch_prediction_job():
try:
vertexai.init(project=os.getenv("PROJECT_ID"), location=os.getenv("PROJECT_LOCATION"))
job = BatchPredictionJob.submit(
source_model=os.getenv("MODEL_ID"), # source_model
input_dataset=f"bq://{os.getenv("BQ_TABLE_ID")}", # input_dataset
output_uri_prefix=f"bq://{os.getenv("BQ_OUTPUT_DATASET")}" # Optional, output_uri_prefix
)
# Check job status
print(f"Job resource name: {job.resource_name}")
print(f"Model resource name with the job: {job.model_name}")
print(f"Job state: {job.state.name}")
# Refresh the job until complete
while not job.has_ended:
time.sleep(5)
job.refresh()
# Check if the job succeeds
if job.has_succeeded:
print("Job succeeded!")
return "Job succeeded!", True
else:
print(f"Job failed: {job.error}")
return f"Job failed: {job.error}", False
# Check the location of the output
print(f"Job output location: {job.output_location}")
# List all the GenAI batch prediction jobs under the project
for bpj in BatchPredictionJob.list():
print(f"Job ID: '{bpj.name}', Job state: {bpj.state.name}, Job model: {bpj.model_name}")
except Exception as err:
return err, False
if __name__ == "__main__":
create_batch_prediction_job()
Conclusion
I think batching is a great idea. Its defiantly something that i will be using in the future. My next plan is to test it with images classification and possibly use it for generating embeddings.
The question is will I use Flash or will I stick with Pro. Flash is nice due to the fact that its cheaper. I think it will depend up on what I am working with. Somethings I think Pro is still better.